2025-02-03 graphs lecture 4
Clean: INPUT[toggle(offValue(0), onValue(1)):clean] Linked: INPUT[toggle(offValue(0), onValue(1)):linked] Publish: INPUT[toggle(offValue(0), onValue(1)):dg-publish]
Maturity: INPUT[inlineSelect(option(seed), option(sprout), option(sapling), option(tree), option(snag), defaultValue(sprout)):maturity]
2025-02-03
- arbitrary linear graph filters
- graph convolution
- spectral representation of a convolutional graph filter
- conditions for finding a convolutional graph filter
Today
- Filter design
- Spectral filters
- filter learning
- statistical learning and ERM
- Types of learning problems on graphs
1. Graph Signals and Graph Signal Processing
Suppose we want to design a lowpass filter for some graph signal.
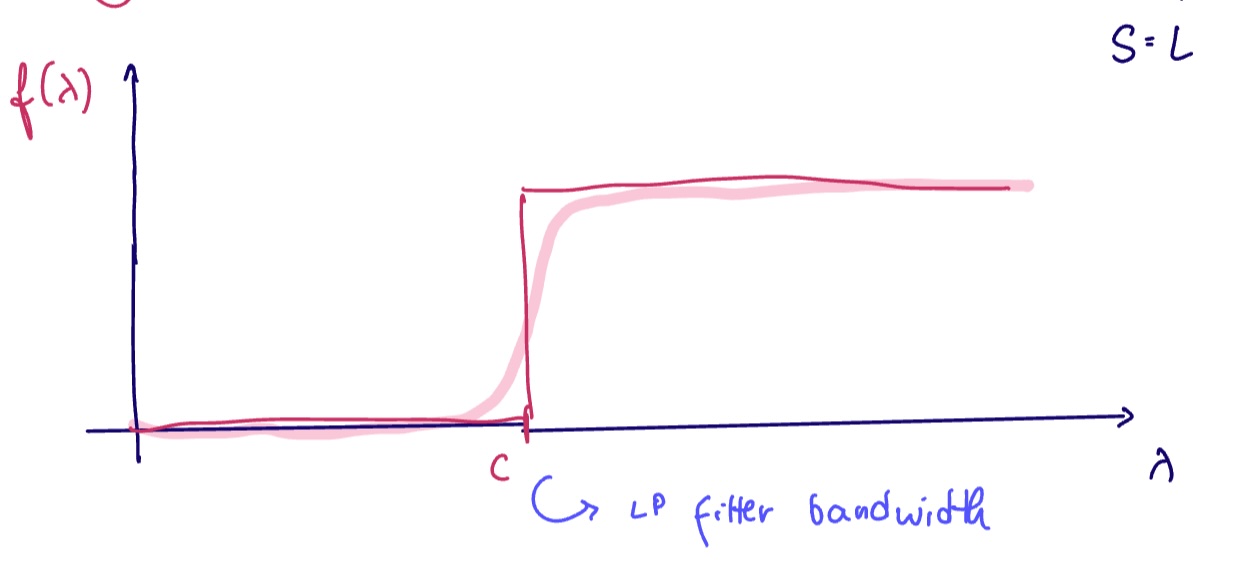
(What does this mean? Consider radio stations: these have carrier waves, which are at higher frequencies than the information to be broadcast. We would need a way to get rid of the carrier frequency to get the desired signal)
Suppose we want to implement this using graph convolutions. Recall that we can represent any analytic function with convolutional graph filters.
Is this function analytic?
No, but we can often find good analytic approximations of non-analytic functions. For heaviside functions such as the lowpass filter, a good approximation is the logistic function
Where
We can approximate heaviside functions using the logistic function as a proxy for our target function
Logistic functions are analytic, and recall that we can represent any analytic function with convolutional graph filters.
As an illustration, we want to find coefficients
Here,
Then
(see approximation of heaviside functions using convolutional graph filters)
So we can do this. That's great! But it can be costly to compute this approximation, especially the higher order derivatives of this function. Is there a better way to design such a filter?
Let
Where
(see spectral graph filter)
Let
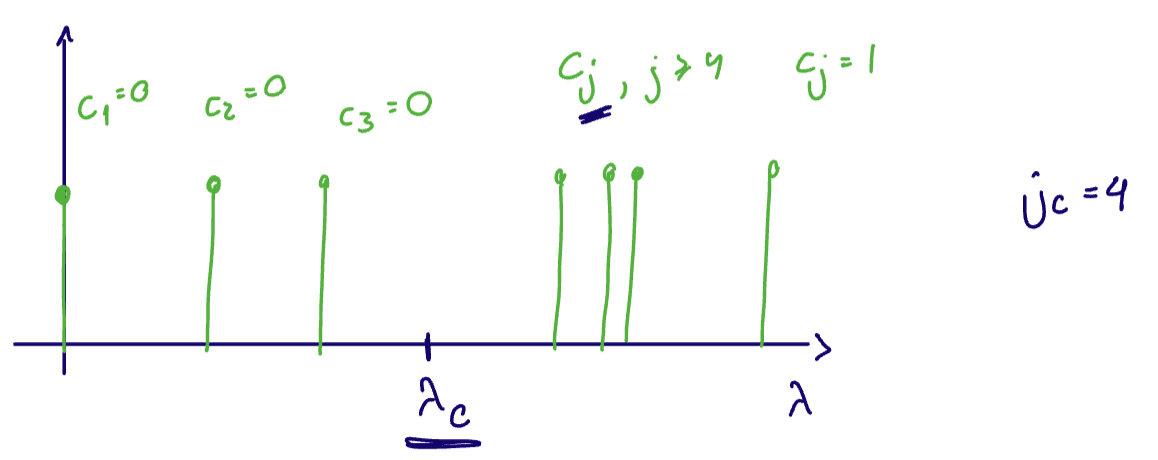
Suppose we want a lowpass filter with bandwith
In model applications, we have moved away from system engineering to learning systems from data.
Supervised Statistical Learning
Suppose
How do we pick the best estimator
- Define a loss function
measuring the "cost" of predicting when the output is
Suppose
Let
The optimal estimator
Typically, we are interested in either
- Predicting
from with the convolutional distribution . - ex: stochastic outputs: VAEs, diffusion, etc
- Predicting
from with the conditional expectation - ex: deterministic outputs, classical regime/supervised learning
What is the issue with this?
In practice we only have access to the data. So instead, we can only estimate the risk according to the data
Consider again the statistical risk minimization problem where we wish to estimate
Suppose we have samples
ie we minimize the empirical mean
Typical loss functions for the ERM are
- quadratic /
loss for regression/estimation problems loss for classification problems - since we often require differentiation, this is often replaced with a differentiable surrogate like cross entropy loss or logistic loss
The ERM problem might have a closed-form solution (line in linear regression), but in modern ML, it is solved using optimization algorithms such as SGD or ADAM.
Types of Graph Signal Processing Problems
Where do our filters fit into ERM?
Our hypothesis class are graph convolutional filters
We usually see 3 types of problems
Graph Signal Processing Problem
In a graph signal processing problem (or graph regression or signal regression), the graph
Here, the hypothesis class are the graph convolutions
Our minimization problem is then $$\min_{h_{k}} \frac{1}{M}\sum_{j} \ell\left( y^{(j)}, \sum_{k=0}^{K-1}h_{k} S^k x^k \right)$$
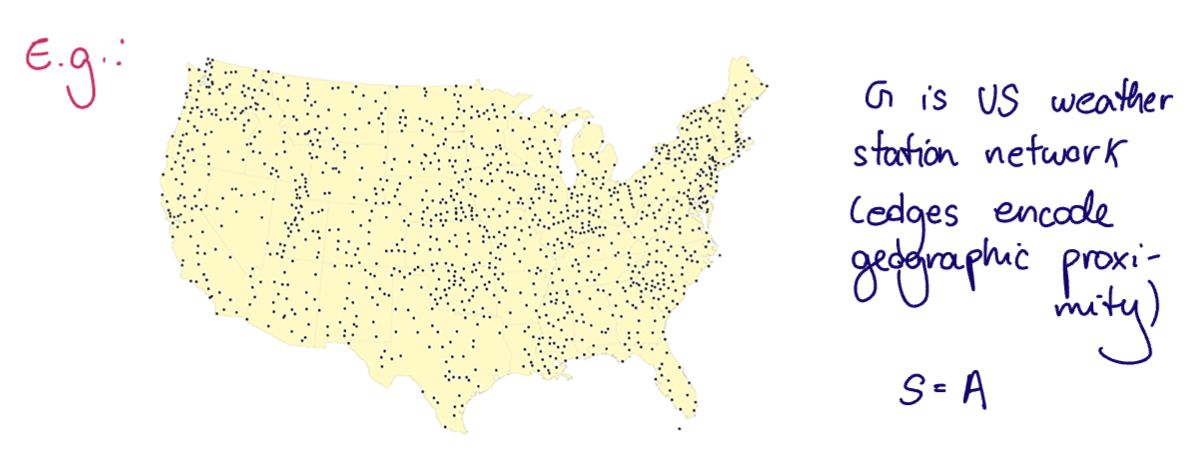
The fixed graph is the US weather station network. Suppose we have our
- Temperatures on the graph are recorded as time series and
- we want to predict the february temperatures from the november temperatures.
Application: temperature forecasting. Predict february 2026 temperatures
Using
Graph-Level Problems
In graph-level problems, there are multiple graphs. Each graph
Here, our hypothesis class is
Since there are no graph signal observations, we use the vector of all ones
And our minimization problem is given by $$\min_{h_{k}} \frac{1}{m} \sum_{i=1}^M \ell\left( \sum_{k=0}^{K-1} h_{k} S^k \mathbb{1}, y \right)$$
(see graph-level problem)
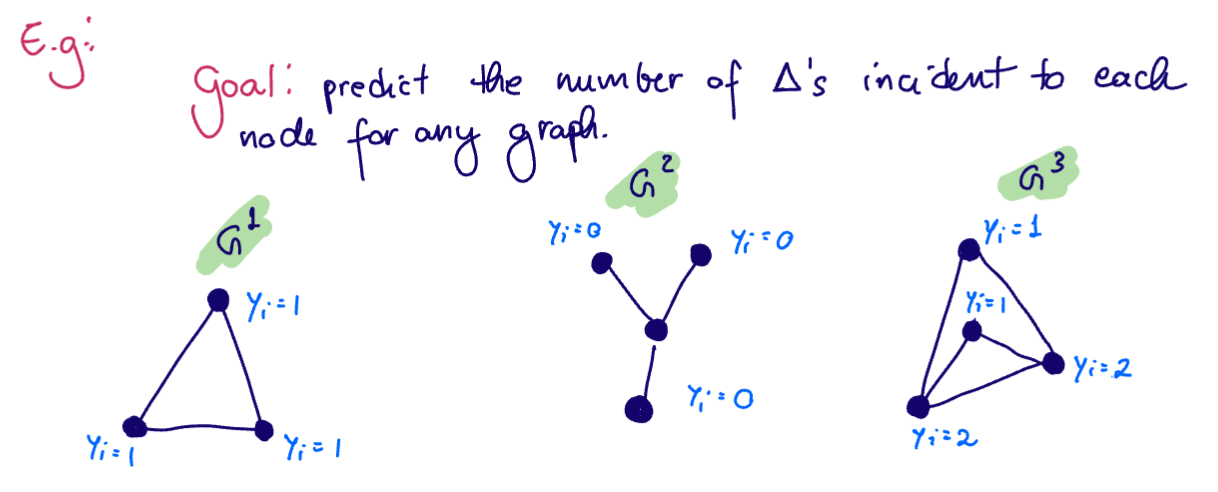
Suppose we want to predict the number of triangles incident to each node for any graph
In this example, since our output is an integer, it mades sense to use the
Application: automate triangle counting
Both the graph signal processing problem and the graph-level problem are supervised learning (sometimes called transductive learning) problems. ie none of the test inputs are seen at training time.
(see supervised learning)
Node-Level Tasks
Node-level tasks (sometimes called inductive learning or semi-supervised learning) have graph
We assume we only observe
(see node-level task)
Consider the contextual SBM:
- If
then and - if
then
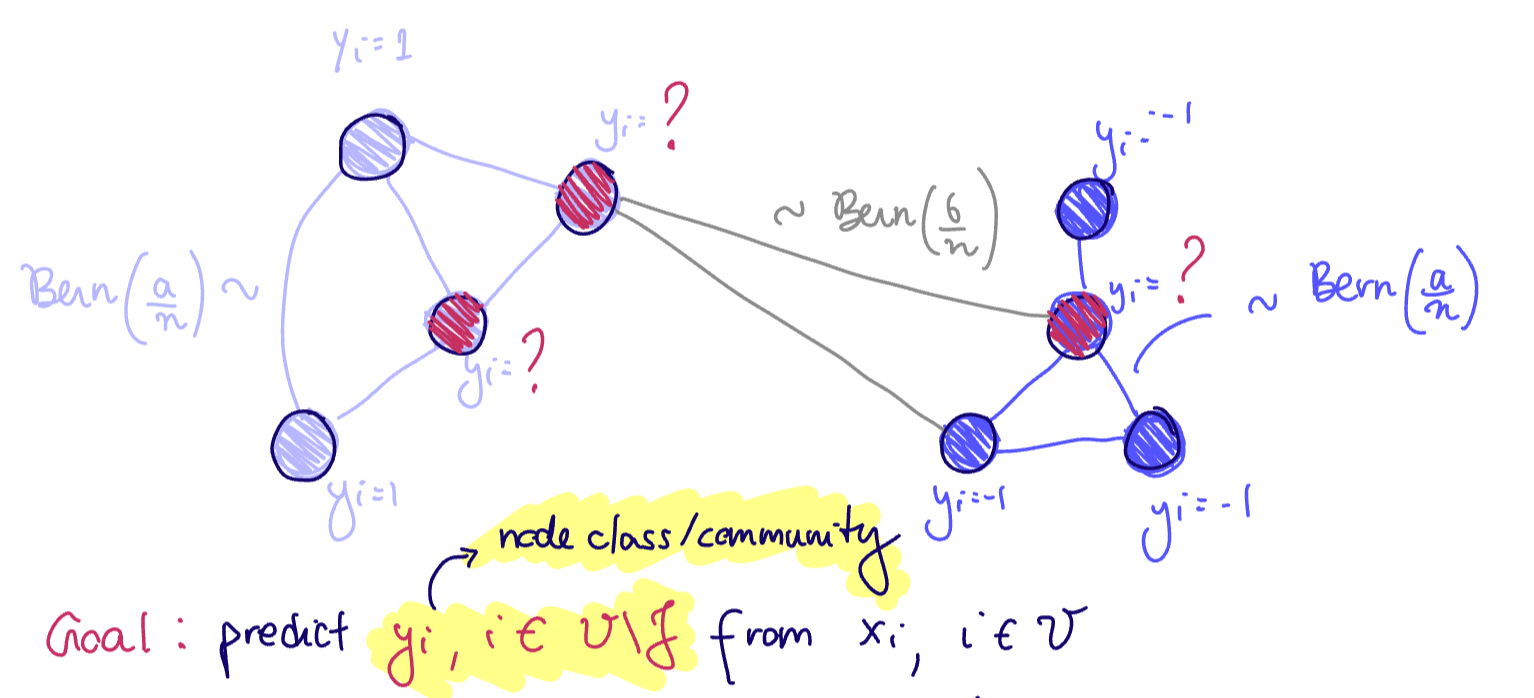
Goal: predict
hypothesis class: the graph convolutions
Problem: Define a mask
Application: infer node's class/community/identity locally ie without needing communication, determining clustering techniques, which require eigenvectors (global graph information)
This problem is an example of inductive learning or semi-supervised learning because the test data
(see lots of techniques from Probabilistic Machine Learning for some of the ways we can do this)
Housekeeping: bring computer next week for pytorch tutorial